
From LLMs to RAG Pipelines: How to Build Production-Ready GenAI Teams with gNxt Systems
Generative AI has rapidly shifted from a buzzword to a core enterprise priority. Organizations across industries are investing heavily in Large Language Models (LLMs) to enhance automation, accelerate knowledge retrieval, streamline workflows, and improve customer experiences. But many enterprises soon discover that the path from GenAI experimentation to production-grade AI systems is both complex and full of operational caveats and requires robust production ready GenAI Teams.
Unlike standalone LLM prototypes, production-ready GenAI requires robust data architecture, governance, security, observability, and — above all — the right engineering team capable of navigating these complex interdependencies.
This blog explains how organizations can move confidently from LLM experimentation to scalable RAG (Retrieval-Augmented Generation) pipelines, and how gNxt Systems enables enterprises to build GenAI teams that deliver secure, responsible, and reliable GenAI solutions that drive business value.
Why Most GenAI Projects Never Reach Production
Many enterprises start their AI journey by integrating an LLM API into a simple chatbot or search interface. During early trials, responses may appear impressive, leading stakeholders to believe that production will follow effortlessly. However, once systems are exposed to real enterprise workloads, significant issues emerge.
LLM output can hallucinate unverified or incorrect facts. Responses lack grounding in proprietary data. Token usage spikes unpredictably, driving up operational costs. Data governance teams raise alarms about exposure of sensitive information. And customers or internal users raise concerns about accuracy and consistency.
This isn’t a defect of the custom model or the underlying LLM—it reflects a deeper architectural gap. Production systems must integrate real enterprise data securely and go beyond the model’s static training set. They must handle concurrency, performance, compliance, and observability at scale — all while optimizing for cost.
To build reliable applications that scale across the enterprise, organizations must embrace architectures like Retrieval-Augmented Generation (RAG) rather than relying solely on out-of-the-box LLM responses.
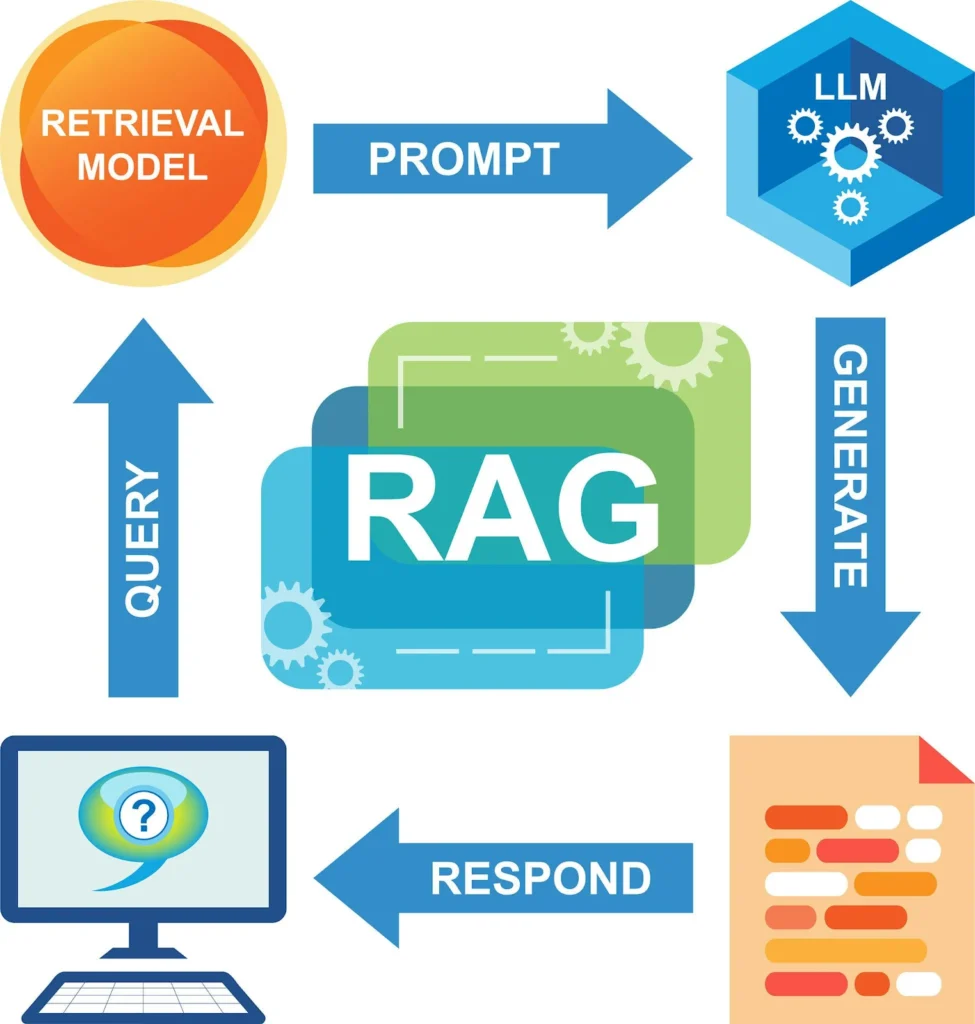
Why RAG Pipelines Are the Enterprise Standard for GenAI
At its core, RAG enhances LLMs by retrieving relevant information from external data sources before generating a response — grounding outputs in up-to-date enterprise data rather than the model’s training data alone. This fundamentally changes reliability, relevance, and factual accuracy.
In a traditional generative model, the LLM generates responses based on probabilistic patterns learned during training, which may not reflect a company’s real data. RAG systems first perform a retrieval step to fetch relevant enterprise knowledge, then feed that context into the LLM for generation. This leads to significantly higher relevance and accuracy, especially when dealing with domain-specific information.
For an enterprise deploying a compliance assistant, product knowledge base, internal helpdesk AI, or legal research tool, RAG delivers responses grounded in proprietary documentation, policy manuals, or curated datasets. This reduces hallucinations and supports traceability — a critical requirement for regulated industries such as healthcare, finance, and energy.
The Hidden Engineering Complexity Beyond Model APIs
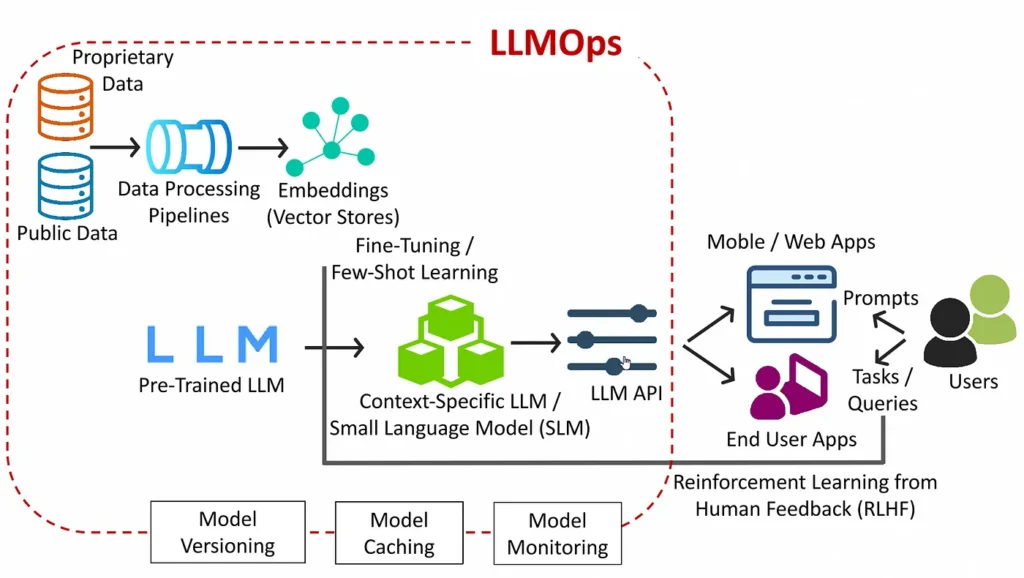
Deploying RAG is not simply about hooking up a vector database and calling an API. A production-grade RAG pipeline must implement reliable data ingestion, embedding creation, vector indexing, retrieval optimization, concurrency management, prompt orchestration, caching, and fail-safe mechanisms.
It also requires LLMOps, an emerging discipline that extends traditional MLOps with dedicated practices for managing the lifecycle of large language models — including monitoring, version control, prompt evaluation, drift detection, observability, and governance.
Modern enterprises rapidly realize that GenAI systems behave very differently from traditional software. Their behavior depends not only on code but on evolving data, prompt design, context windows, retrieval quality, and model updates. This continuous dynamic requires disciplined engineering practices that many internal teams are not yet structured to handle.
How gNxt Systems Builds Production-Grade GenAI Teams
Unlike vendors who provide individual engineers or loosely assembled talent pools, gNxt Systems approaches GenAI as an engineering capability — one that requires coordination, ownership, and integration across disciplines.
gNxt Systems begins with a capability assessment of both data and organizational readiness. This assessment evaluates data quality, compliance constraints, infrastructure maturity, security requirements, scale expectations, and performance goals. Far from a one-size-fits-all deployment, this enables teams to architect RAG pipelines that are aligned with enterprise governance and operational best practices.
Once requirements are clear, gNxt Systems assembles a multi-disciplinary GenAI team that bridges traditionally siloed functions: AI/ML engineers, data pipeline specialists, backend developers, cloud infrastructure architects, DevOps/LLMOps practitioners, and security leads all work in unified squads with shared responsibility for outcomes.
This structure ensures that models are not only deployed but also continuously maintained with best-in-class operational practices — allowing enterprises to scale GenAI beyond pilots into full production deployments that deliver measurable business impact.
How gNxt Systems Enables Continuous Governance and Monitoring
Enterprise AI governance has become a strategic imperative. As AI systems increasingly impact workflows, decision-making, and customer interaction, enterprises must ensure they are auditable, traceable, and compliant with internal and external policies.
Modern GenAI implementations now prioritize continuous monitoring and evaluation of both technical performance (latency, throughput, relevance) and business signals (accuracy, user satisfaction, compliance alignment). Enterprises that ignore these requirements risk costly errors, reputational damage, or regulatory scrutiny.
gNxt Systems Staff Augmentation process embeds governance frameworks into GenAI team processes. Teams implement evaluation frameworks that continuously test outputs against benchmarks, ensuring content remains aligned with enterprise standards. Monitoring dashboards alert stakeholders to anomalies, performance degradation, or drift, enabling proactive adjustments.
This combination of architecture discipline and governance oversight turns GenAI systems into reliable tools rather than ad-hoc experiments.
The Strategic Advantage: From Short-Term Wins to Long-Term Value
As enterprises become more mature in their AI adoption, they pivot from use cases built in isolation toward AI ecosystems integrated with core enterprise systems. These organizations invest in AI platforms that support multiple internal customers — from HR knowledge assistants to customer support automation to domain-specific research tools.
The enterprises that succeed in this evolution treat GenAI not as a marketing initiative, but as a strategic engineering investment that enhances workflows, accelerates knowledge access, and improves decision-making.
With gNxt Systems’ engineering-first focus, enterprises get more than a one-off implementation; they build durable GenAI capability that delivers value across teams and departments.
Frequently Asked Questions (FAQ)
Q1. What is Retrieval-Augmented Generation (RAG) and why does it matter?
Q2. How does a RAG pipeline differ from a simple LLM API setup?
Q3. What are the main challenges in deploying RAG in production?
Q4. Do enterprises need dedicated teams to build and maintain GenAI systems?
Q5. How do enterprises measure the success of a RAG-based GenAI system?
About Author

CEO at gNxt Systems
with 25+ years of expertise, Mr. Anoop Jain delivers complex projects, driving innovation through IT strategies and inspiring teams to achieve milestones in a competitive, technology-driven landscape.