
- March 19, 2026
- by Anoop Jain
From LLMs to LLMOps: The New Era of GenAI Staffing
Generative AI has entered a new phase of enterprise adoption. What began as rapid experimentation with large language models (LLMs) has now evolved into a strategic priority for organizations across industries. From banking and healthcare to retail, manufacturing, and SaaS, enterprises are actively integrating AI into their core operations, indicating a dire need for a perfect GenAI Staffing Infrastructure.
However, as organizations move from proof-of-concept initiatives to production-scale deployments, a fundamental shift is becoming evident. The challenge is no longer about accessing powerful models or building initial applications. The real challenge lies in operationalizing these systems reliably, securely, and at scale.
This transition marks the emergence of LLMOps (Large Language Model Operations) — a discipline that is redefining how enterprises build, manage, and scale Generative AI systems. Alongside this shift, a new reality is reshaping workforce strategies: GenAI staffing is no longer about hiring isolated AI engineers; it is about building integrated, production-ready AI teams.
The Evolution from LLM Adoption to Enterprise AI Systems
In the early stages of Generative AI adoption, organizations focused primarily on leveraging LLM APIs to build quick solutions. These included AI-powered chatbots, internal knowledge assistants, automated documentation tools, and customer support systems. The barrier to entry was low, and the results were often impressive enough to generate internal momentum.
However, as these systems began interacting with real enterprise data and users, limitations quickly surfaced. Organizations encountered inconsistent outputs, hallucinated responses, rising API costs, latency challenges, and growing concerns around data privacy and compliance.
These issues are not failures of the underlying models. Instead, they reflect the absence of a structured operational framework. LLMs, by their nature, are probabilistic systems. Their outputs depend heavily on context, data quality, and system design. Without proper monitoring, governance, and optimization, even the most advanced models can produce unreliable results.
This is where enterprises begin to recognize the need for a more mature approach — one that treats AI not as a feature, but as a core engineering system requiring lifecycle management.
Understanding LLMOps in the Enterprise Context
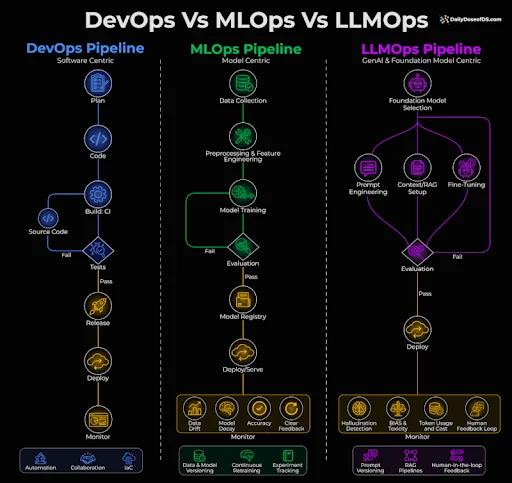
LLMOps introduces the processes, tools, and governance frameworks required to manage Generative AI systems in production. It extends beyond traditional MLOps by addressing challenges unique to large language models, including prompt management, context retrieval, token consumption, and output variability.
In an enterprise environment, LLMOps enables organizations to bring predictability and control to AI systems. It ensures that models behave consistently, that outputs can be evaluated and improved over time, and that operational risks are minimized.
More importantly, LLMOps transforms AI from an experimental capability into an operational discipline. It introduces observability, enabling teams to track how AI systems perform under different conditions. It provides mechanisms to optimize cost, particularly in environments where token usage can escalate rapidly. It embeds security and compliance into the system architecture, ensuring that sensitive enterprise data is protected.
Without LLMOps, AI deployments remain fragile and difficult to scale. With it, they become reliable components of enterprise infrastructure.
The Hidden Complexity Behind Production-Ready GenAI Systems
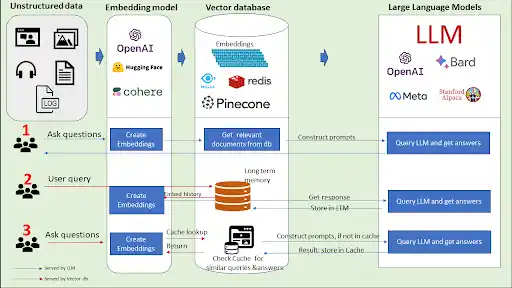
One of the most common misconceptions in Generative AI adoption is that integrating an LLM API is sufficient to build a scalable solution. In reality, production-grade GenAI systems involve multiple interconnected layers.
These systems require robust data pipelines that ingest and process enterprise data in real time. They rely on vector databases to enable semantic search and contextual retrieval. Retrieval-Augmented Generation (RAG) pipelines must be carefully designed to ensure that the model receives accurate and relevant context.
In addition, AI systems must be integrated with backend services, APIs, and user interfaces. They must operate within secure environments that enforce access controls and data governance policies. Continuous monitoring is required to detect performance issues, output inconsistencies, and cost anomalies.
All of this must function seamlessly under real-world conditions, where multiple users interact with the system simultaneously, and where reliability is non-negotiable.
This level of complexity cannot be managed by a single role or a loosely structured team. It requires coordinated expertise across multiple domains.
Why Traditional AI Hiring Models Are No Longer Sufficient
Many organizations still approach Generative AI staffing using traditional frameworks. They hire data scientists, machine learning engineers, or backend developers and expect these roles to collectively deliver production-ready AI systems.
While these roles remain important, they are not sufficient on their own.
Generative AI introduces new requirements that were not part of earlier AI systems. Prompt engineering must be treated as a structured discipline rather than an ad hoc activity. RAG architectures must be designed to ensure accuracy and relevance. Token usage must be optimized to control operational costs. Systems must be monitored continuously to detect drift, hallucinations, and performance degradation.
These requirements demand specialized expertise that goes beyond conventional AI roles.
As a result, enterprises are increasingly realizing that success in Generative AI depends not just on hiring individuals, but on building the right team architecture.
The Rise of LLMOps-Driven Team Structures
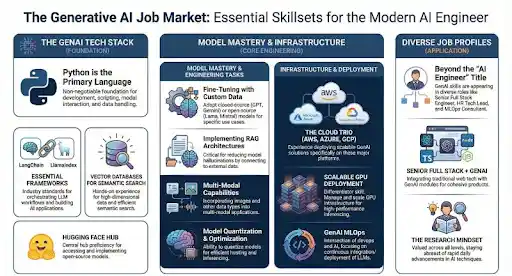
The new era of GenAI staffing is defined by cross-functional, LLMOps-driven teams. These teams bring together expertise across AI engineering, data engineering, platform development, and operational management.
A production-ready GenAI team typically includes professionals who can design and integrate LLM-based applications, engineers who can build and manage data pipelines, specialists who can monitor and optimize AI systems, and experts who ensure security and compliance.
What differentiates these teams is not just technical capability, but coordination. Each role contributes to a system that must function as a cohesive whole.
To give an example example, an AI engineer may design prompts and model interactions, but the effectiveness of those prompts depends on the quality of data provided by the data pipeline. Similarly, the scalability of the system depends on how well backend engineers and DevOps specialists manage infrastructure. Security teams must ensure that sensitive data is handled appropriately at every stage.
This interconnected structure reflects a broader shift in enterprise technology: systems thinking is replacing role-based execution.
The Strategic Role of Staff Augmentation in the LLMOps Era
Building LLMOps-ready teams internally presents significant challenges. The demand for experienced GenAI professionals is growing rapidly, and the supply of talent with production-level experience remains limited.
Hiring such talent through traditional recruitment processes can take months, and even then, it can be difficult to assess whether candidates have real-world experience with enterprise-scale AI systems.
This is where proper Gen AI Staffing ecosystem/infrastructure has become a critical need.
By working with specialized staffing partners, enterprises can access experienced AI engineers, data specialists, and LLMOps professionals who have already worked on production systems. These professionals can be integrated into existing teams, enabling organizations to accelerate development while maintaining control over their projects.
Staff augmentation also provides flexibility. As AI initiatives evolve, organizations can scale teams up or down based on project requirements, reducing the risk associated with long-term hiring commitments.
In the context of LLMOps, this flexibility is particularly valuable. AI systems evolve rapidly, and teams must adapt to new tools, frameworks, and requirements. A flexible staffing model allows enterprises to stay agile while maintaining operational stability.
India’s Growing Role in LLMOps and GenAI Talent
India has emerged as a key destination for building Generative AI and LLMOps capabilities. The country’s strong foundation in software engineering, cloud computing, and data engineering provides a natural pathway into advanced AI operations.
Global Capability Centers (GCCs) in India are increasingly taking ownership of AI platforms, data infrastructure, and digital transformation initiatives. This has accelerated the development of specialized talent in areas such as LLM integration, RAG architecture, and AI operations.
Especially for global enterprises, India offers a combination of scale, technical expertise, and cost efficiency. However, the market is becoming increasingly competitive, particularly for professionals with hands-on experience in production-grade AI systems.
This makes it even more important to adopt structured staffing strategies and work with partners who understand the nuances of GenAI and LLMOps.
The Future of GenAI Staffing
As Generative AI continues to evolve, staffing strategies will need to evolve with it. The focus will shift from hiring individual specialists to building integrated teams that can manage the full lifecycle of AI systems.
Enterprises will prioritize operational maturity over rapid experimentation. They will invest in observability, governance, and continuous improvement. They will design teams that can adapt to changing technologies while maintaining system stability.
In this new landscape, success will depend on the ability to align talent with technology.
Organizations that recognize this shift early will be better positioned to scale AI effectively. Those that continue to rely on outdated hiring models may struggle to move beyond experimentation.
Conclusion
The transition from LLMs to LLMOps represents a fundamental shift in enterprise AI adoption. It reflects a move from experimentation to operational maturity, from isolated use cases to integrated systems, and from individual roles to coordinated teams.
For enterprises, this shift requires a new approach to staffing. Success in Generative AI is no longer about hiring a few skilled individuals. It is about building teams that can design, deploy, and operate AI systems at scale.
As AI becomes a core component of enterprise strategy, staffing will play a critical role in determining outcomes.
In the era of LLMOps, the question is no longer whether organizations can build AI solutions.
It is whether they can run them effectively.
Q1. What is LLMOps and why is it important for enterprises?
Q2. What is the difference between LLM and LLMOps?
Q3. What roles are needed for LLMOps teams?
Q4. Why do companies struggle to scale Generative AI projects?
Q5. How can enterprises build production-ready GenAI teams?
About Author

CEO at gNxt Systems
with 25+ years of expertise, Mr. Anoop Jain delivers complex projects, driving innovation through IT strategies and inspiring teams to achieve milestones in a competitive, technology-driven landscape.